Pre-requisites
Idea about Artificial Neural Networks, good if you have familiarity with the ideas of supervised learning, logistic regression, gradient descent, SVM-based classification, k-means clustering, kernel tricks like KPCA, etc.
Motivation
Deep neural networks (DNNs) trained via backpropagation were recently shown to perform well on image classification tasks with lakhs of training images and lot of categories. The feature representation learned by these networks achieves state-of-the-art performance not only on the classification task for which the network was trained, but also on various other visual recognition tasks, for example: classification on various dataset; scene recognition, etc. This capability to generalize to new datasets makes supervised CNN (Convolutional Neural Networks) training an attractive approach for generic visual feature learning.
What is Deep Learning / What makes it “deep”1?

-
1 million parameters
-
10 mil images
-
10 layers!!
That’s what makes it “deep”!
Deep learning methods aim at learning feature hierarchies with features from higher levels of the hierarchy formed by the composition of lower level features. For image classification tasks, the most effective deep networks used nowadays are the Convolutional Neural Networks (others include corrNets, restricted Boltzmann machines, Recurrent Neural Networks, etc.).
Image Classification with CNNs
Each CNN has its own architecture - convolution layers, pooling layers (max pooling, weighted mean pooling, etc), fully connected layers et al.
Three methods of training using a Conv Net:
-
Supervised
-
Unsupervised
-
Reinforcement

The most common method is to learn the network using a huge set of training images. This approach is called the supervised learning of the network. To learn the network implied learning the filters in the convolution layer (filters are also called weights)
It involves 2 phases - Training run and a accuracy testing run
1) Training run: Pick a CNN architecture -> Input a million training images spanning all categories -> One or days of GPU computation
2) Accuracy testing: If the accuracy is bad, fix the training set, tweak the training parameters -> do it again
CNN learnt with supervised learning give a high accuracy for classification tasks and the same network can be used for other tasks too, like scene detection.
Introduction of discriminative Unsupervised learning in Neural Networks
The downside of supervised training is the need for expensive labeling, as the amount of required labeled samples grows quickly the larger the model gets. For this reason, unsupervised learning remains an appealing paradigm, since it can make use of raw unlabeled images and videos. Furthermore, on vision tasks outside classification it is not even certain whether training based on object class labels is advantageous. For example, recent results show that it outperforms supervised feature learning also on descriptor matching.
In Unsupervised learning, the filter (or weights) are not learnt directly from the training images. Sometimes, a predefined set of filters is chosen - best example being the Gabor filters - or the filters are extracted from the images ‘patches’ with some processing done on them.
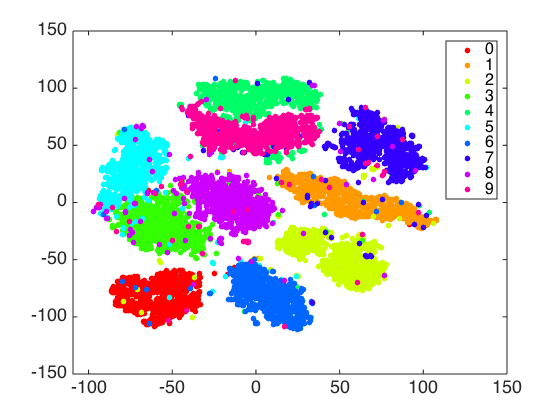
fig: MNIST dataset classification using k-means clustering
A common framework used in unsupervised feature learning is 2 :
-
Extract random patches from unlabeled training images.
-
Apply a pre-processing stage to the patches.
-
Learn a feature-mapping using an unsupervised learning algorithm.
Given the learned feature mapping and a set of labeled training images we can then perform feature extraction and classification:
-
Extract features from equally spaced sub-patches covering the input image.
-
Pool features together over regions of the input image to reduce the number of feature values.
-
Train a classifier to predict the labels given the feature vectors.
Conclusion
Image classification results can be hugely increased using some preprocessing (can be anything depending on the application). It is common practice to perform several simple normalization steps before attempting to generate features from data. In Unsupervised feature extraction, there are also some tricks like the ‘kernel trick’ which can improve the classification results.
The feature vector length can always be reduced using some fully connected layers in the network. This can help speed-up the classification, but must be used carefully as to not compromise the accuracy. Much future work is going on in the direction of using unsupervised or semi-supervised neural networks, since as of now they are not very scalable.
Deep learning, CNNs, corrNets, etc are THE most active fields in data analytics. And I believe can be learnt only through experimentation! So feel free to explore this ocean of deep learning! Enjoy!
Regards,
Yash Bhalgat.
[1]: deep learning for image classification - Nvidia. 2015. 15 May.
[2]: Coates, A. “An Analysis of Single-Layer Networks in Unsupervised Feature Learning.” 2011.